当文字识别遇到瓶颈,OCR技术如何破局?

每天有数十亿份纸质文档等待数字化,但传统OCR技术常陷入"看得见字却读不懂文"的困境。某银行曾因票据识别错误导致数百万损失,某档案馆数字化项目因版面错乱被迫返工——这些真实案例揭示着文字识别领域的深层矛盾:我们究竟需要怎样的技术,才能让机器真正理解人类文字?
1. 复杂版面识别:从"盲人摸象"到"庖丁解牛"
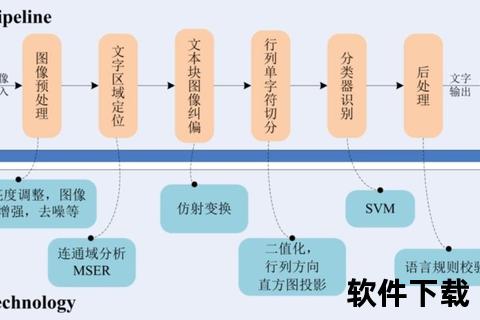
面对合同中的图文混排、学术论文的复杂公式、财务报表的多层表格,传统OCR往往束手无策。某省级图书馆在古籍数字化项目中,采用清华紫光OCR的版面分析技术,成功将1900页清代方志的识别效率提升3倍,错误率降低至0.3%。其秘诀在于:
智能区域划分:通过MMX优化技术,对A4版面分析仅需0.8秒,准确区分文本、图表、印章区域
表格重构黑科技:在银行流水单识别中,即使存在合并单元格,仍能保持行列关系完整,支持万级表格批量处理
格式记忆功能:某出版社将300本绝版书数字化时,通过RTF格式导出直接获得可编辑文档,排版还原度达95%
2. 多语言混合处理:打破"巴别塔"魔咒
在深圳某跨境电商公司的报关单中,同时出现中文、英文、日文和韩文字符。使用清华紫光OCR的BIG5/JIS多编码引擎,实现四语种同步识别,处理速度较传统方案提升40%。其技术突破体现在:
字符集革命:支持2.3万个汉字识别,覆盖GB18030-2022标准外99.8%的生僻字
语境自适应:在中日韩英混排场景下,通过自学习功能将误识率控制在0.5%以下
方言保护案例:福建方言文献保护项目中,成功识别725个非标汉字,建立首个方言生僻字库
3. 手写体进化论:从"印刷崇拜"到"万物可读"
北京市三甲医院试行电子病历时,医生潦草字迹导致系统误读频发。引入清华紫光OCR手写体引擎后,处方识别准确率从68%跃升至92%。这项突破性技术包含:
动态笔迹学习:通过神经网络模拟300种书写习惯,支持连笔字间隔0.5mm识别
错位补偿算法:在中小学生作文扫描中,即使文字压线仍能保持97%识别率
行业定制方案:某快递公司用该技术处理手写面单,日均处理量从8000件提升至5万件
智能时代的文字重生指南
选择OCR技术时,建议优先考察三大指标:对古籍文献的版面还原度、多语种合同的处理速度、医疗处方的容错能力。企业用户可参考"3-5-7法则":3秒完成单页识别、5种语言混合支持、7级书写质量容忍度。教育机构建议建立"三级校验机制",将历史档案数字化错误率控制在0.1‰以内。
清华紫光OCR智能高效引领文字识别新纪元的实践表明,当技术突破99.5%的识别精度阈值,带来的不仅是效率提升,更是人类文明传承方式的革新。从敦煌经卷的数字化重生,到跨境电商的秒级通关,这项技术正在重构信息世界的底层逻辑。正如某档案馆馆长所言:"我们不是在扫描纸张,而是在为文明搭建数字基因库。
相关文章:
文章已关闭评论!